Sharding codec (version 1.0)#
- Specification URI:
https://zarr-specs.readthedocs.io/en/latest/v3/codecs/sharding-indexed/v1.0.html
- Editors:
Jonathan Striebel (@jstriebel), Scalable Minds
Norman Rzepka (@normanrz), Scalable Minds
Jeremy Maitin-Shepard (@jbms), Google
- Corresponding ZEP:
- Issue tracking:
- Suggest an edit for this spec:
Copyright 2022-Present Zarr core development team. This work is licensed under a Creative Commons Attribution 3.0 Unported License.
Abstract#
This specification defines a Zarr array -> bytes codec for sharding.
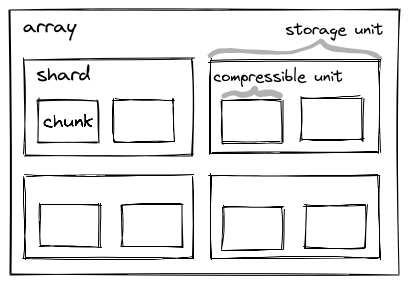
Sharding logically splits chunks (“shards”) into sub-chunks (“inner chunks”) that can be individually compressed and accessed. This allows to colocate multiple chunks within one storage object, bundling them in shards.
Status of this document#
ZEP0002 was accepted on November 1st, 2023 via zarr-developers/zarr-specs#254.
Motivation#
In many cases, it becomes inefficient or impractical to store a large number of chunks as separate files or objects due to the design constraints of the underlying storage. For example, the file block size and maximum inode number restrict the usage of numerous small files for typical file systems, also cloud storage such as S3, GCS, and various distributed filesystems do not efficiently handle large numbers of small files or objects.
Increasing the chunk size works only up to a certain point, as chunk sizes need to be small for read efficiency requirements, for example to stream data in browser-based visualization software.
Therefore, chunks may need to be smaller than the minimum size of one storage key. In those cases, it is efficient to store objects at a more coarse granularity than reading chunks.
Sharding solves this by allowing to store multiple chunks in one storage key, which is called a shard:
Document conventions#
Conformance requirements are expressed with a combination of descriptive assertions and [RFC2119] terminology. The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in the normative parts of this document are to be interpreted as described in [RFC2119]. However, for readability, these words do not appear in all uppercase letters in this specification.
All of the text of this specification is normative except sections explicitly marked as non-normative, examples, and notes. Examples in this specification are introduced with the words “for example”.
Codec name#
The value of the name member in the codec object MUST be sharding_indexed.
Configuration parameters#
Sharding can be configured per array in the Array metadata as follows:
{
"codecs": [
{
"name": "sharding_indexed"
"configuration": {
"chunk_shape": [32, 32],
"codecs": [
{
"name": "bytes",
"configuration": {
"endian": "little",
}
},
{
"name": "gzip",
"configuration": {
"level": 1
}
}
],
"index_codecs": [
{
"name": "bytes",
"configuration": {
"endian": "little",
}
},
{ "name": "crc32c" }
],
"index_location": "end"
}
}
]
}
chunk_shape
An array of integers specifying the shape of the inner chunks in a shard along each dimension of the outer array. The length of the
chunk_shapearray must match the number of dimensions of the shard shape to which this sharding codec is applied, and the inner chunk shape along each dimension must evenly divide the size of the shard shape. For example, an inner chunk shape of[32, 2]with an shard shape[64, 64]indicates that 64 inner chunks are combined in one shard, 2 along the first dimension, and for each of those 32 along the second dimension.
codecs
Specifies a list of codecs to be used for encoding and decoding inner chunks. The value must be an array of objects, as specified in the Array metadata. The
codecsmember is required and needs to contain exactly onearray -> bytescodec.
index_codecs
Specifies a list of codecs to be used for encoding and decoding shard index. The value must be an array of objects, as specified in the Array metadata. The
index_codecsmember is required and needs to contain exactly onearray -> bytescodec. Codecs that produce variable-sized encoded representation, such as compression codecs, MUST NOT be used for index codecs. It is RECOMMENDED to use a little-endian codec followed by a crc32c checksum as index codecs.
index_location
Specifies whether the shard index is located at the beginning or end of the file. The parameter value must be either the string
startorend. If the parameter is not present, the value defaults toend.
Definitions#
Shard is a chunk of the outer array that corresponds to one storage object. As described in this document, shards MAY have multiple inner chunks.
Inner chunk is a chunk within the shard.
Shard shape is the chunk shape of the outer array.
Inner chunk shape is defined by the
chunk_shapeconfiguration of the codec. The inner chunk shape needs to have the same dimensions as the shard shape and the inner chunk shape along each dimension must evenly divide the size of the shard shape.Chunks per shard is the element-wise division of the shard shape by the inner chunk shape.
Binary shard format#
This is an array -> bytes codec.
In the sharding_indexed binary format, inner chunks are written successively in a
shard, where unused space between them is allowed, followed by an index
referencing them.
The index is an array with 64-bit unsigned integers with a shape that matches the
chunks per shard tuple with an appended dimension of size 2.
For example, given a shard shape of [128, 128] and chunk shape of [32, 32],
there are [4, 4] inner chunks in a shard. The corresponding shard index has a
shape of [4, 4, 2].
The index contains the offset and nbytes values for each inner chunk.
The offset[i] specifies the byte offset within the shard at which the
encoded representation of chunk i begins, and nbytes[i] specifies the
encoded length in bytes.
Empty inner chunks are denoted by setting both offset and nbytes to 2^64 - 1.
Empty inner chunks are interpreted as being filled with the fill value. The index
always has the full shape of all possible inner chunks per shard, even if they extend
beyond the array shape.
The index is either placed at the end of the file or at the beginning of the file,
as configured by the index_location parameter. The index is encoded into binary
representations using the specified index codecs. The byte size of the index is
determined by the number of inner chunks in the shard n, i.e. the product of
chunks per shard, and the choice of index codecs.
For an example, consider a shard shape of [64, 64], an inner chunk shape of
[32, 32] and an index codec combination of a little-endian codec followed by
a crc32c checksum codec. The size of the corresponding index is
16 (2x uint64) * 4 (chunks per shard) + 4 (crc32c checksum) = 68 bytes.
The index would look like:
| chunk (0, 0) | chunk (0, 1) | chunk (1, 0) | chunk (1, 1) | |
| offset | nbytes | offset | nbytes | offset | nbytes | offset | nbytes | checksum |
| uint64 | uint64 | uint64 | uint64 | uint64 | uint64 | uint64 | uint64 | uint32 |
The actual order of the chunk content is not fixed and may be chosen by the implementation. All possible write orders are valid according to this specification and therefore can be read by any other implementation. When writing partial inner chunks into an existing shard, no specific order of the existing inner chunks may be expected. Some writing strategies might be
Fixed order: Specify a fixed order (e.g. row-, column-major, or Morton order). When replacing existing inner chunks larger or equal-sized inner chunks may be replaced in-place, leaving unused space up to an upper limit that might possibly be specified. Please note that, for regular-sized uncompressed data, all inner chunks have the same size and can therefore be replaced in-place.
Append-only: Any chunk to write is appended to the existing shard, followed by an updated index. If previous inner chunks are updated, their storage space becomes unused, as well as the previous index. This might be useful for storage that only allows append-only updates.
Other formats: Other formats that accept additional bytes at the end of the file (such as HDF) could be used for storing shards, by writing the inner chunks in the order the format prescribes and appending a binary index derived from the byte offsets and lengths at the end of the file.
Any configuration parameters for the write strategy must not be part of the metadata document; instead they need to be configured at runtime, as this is implementation specific.
Implementation notes#
The section suggests a non-normative implementation of the codec including common optimizations.
Decoding: A simple implementation to decode inner chunks in a shard would (a) read the entire value from the store into a byte buffer, (b) parse the shard index as specified above from the beginning or end (according to the
index_location) of the buffer and (c) cut out the relevant bytes that belong to the requested chunk. The relevant bytes are determined by theoffset,nbytespair in the shard index. This bytestream then needs to be decoded with the inner codecs as specified in the sharding configuration applying the Decoding procedure. This is similar to how an implementation would access a sub-slice of a chunk.The size of the index can be determined by applying
c.compute_encoded_sizefor each index codec recursively. The initial size is the byte size of the index array, i.e.16 * chunks per shard.When reading all inner chunks of a shard at once, a useful optimization would be to read the entire shard once into a byte buffer and then cut out and decode all inner chunks from that buffer in one pass.
If the underlying store supports partial reads, the decoding of single inner chunks can be optimized. In that case, the shard index can be read from the store by requesting the
nfirst or last bytes (according to theindex_location), wherenis the size of the index as determined by the number of inner chunks in the shard and choice of index codecs. After parsing the shard index, single inner chunks can be requested from the store by specifying the byte range. The bytestream, then, needs to be decoded as above.Encoding: A simple implementation to encode a chunk in a shard would (a) encode the new chunk per Encoding procedure in a byte buffer using the shard’s inner codecs, (b) read an existing shard from the store, (c) create a new bytestream with all encoded inner chunks of that shard including the overwritten chunk, (d) generate a new shard index that is prepended or appended (according to the
index_location) to the chunk bytestream and (e) writes the shard to the store. If there was no existing shard, an empty shard is assumed. When writing entire inner chunks, reading the existing shard first may be skipped.When working with inner chunks that have a fixed byte size (e.g., uncompressed) and a store that supports partial writes, a optimization would be to replace the new chunk by writing to the store at the specified byte range.
On stores with random-write capabilities, it may be useful to (a) place the shard index at the beginning of the file, (b) write out inner chunks in application-specific order, and (c) update the shard index accordingly. Synchronization of parallelly written inner chunks needs to be handled by the application.
Other use case-specific optimizations may be available, e.g., for append-only workloads.
References#
S. Bradner. Key words for use in RFCs to Indicate Requirement Levels. March 1997. Best Current Practice. URL: https://tools.ietf.org/html/rfc2119